Rally − Vom Benchmarking zur kontinuierlichen Verbesserung
Wir können unser hohes Qualitätsniveau nur dann halten, wenn wir unsere Dienste kontinuierlich weiterentwickeln. Dazu müssen wir allerdings eine Möglichkeit finden, Qualität zu definieren und zu messen, Schwankungen zu erkennen und bei Verschlechterungen nachzuforschen.
Hier bietet uns OpenStack (die Lösung, auf der unser Public Cloud Angebot aufgebaut ist), einige Möglichkeiten. Dabei sind zwei Punkte unserer Meinung nach für unsere Kunden wesentlich:
- die Verwendung der OpenStack-API über die OpenStack-Clients, Bibliotheken sowie die OVH-API v6
- garantierte Leistung für Instanzen (Prozessor, RAM, Festplatte, Netzwerk)
Im folgenden Beitrag wollen wir auf den ersten Punkt genauer eingehen und zeigen, wie OVH die Performance der Public Cloud APIs misst. Ich werde unsere Lösung vorstellen und wie wir diese in das Ökosystem von OVH integriert haben. Am Ende beschreibe ich einen konkreten Anwendungsfall, der zeigt, wie wir die Antwortzeiten bestimmter API-Aufrufe um bis zu 75 % verbessern konnten.
Rally − das kundenorientierte Benchmarking-Tool von OpenStack
Die OpenStack-Komponente Rally ist eine „Benchmarking as a Service“-Lösung. Das Tool testet die OpenStack-Umgebung aus Sicht der Kunden und misst die Ausführungszeiten.
Das in Python entwickelte Projekt startete 2013. Version 1.0.0 wurde vor Kurzem, im Juli 2018, veröffentlicht. Dass OVH genau dieses Projekt ausgewählt hat, ist eigentlich selbstverständlich, denn wir sind Teil des OpenStack-Ökosystems und das Tool bietet somit alle Funktionen, die wir benötigen.
Mit Rally lassen sich bestimmte Szenarien durchführen, wie beispielsweise sequentielle Testsets, die mehr oder weniger komplex gestaltet werden können. Es ist zum Beispiel möglich, nur Erstellung und Funktion eines Authentifizierungstokens zu testen. Es lassen sich aber auch komplexere Szenarien umsetzen: Mit einem einzigen Szenario können Authentifizierung und Erstellung mehrerer Instanzen getestet werden, indem ihnen Festplatten hinzugefügt werden. Durch diese Flexibilität können wir ganz einfach und ohne Einschränkungen sehr spezifische Tests entwerfen. In Rally ist nativ bereits eine Vielzahl von kompletten Szenarien verfügbar, die den jeweiligen Funktionskomponenten (zum Beispiel Nova, Neutron, Keystone oder Glance) zugeordnet sind.
Das Tool misst die Antwortzeiten jeder einzelnen Phase des Szenarios ebenso wie die Gesamtantwortzeit. Die Daten werden in Datenbanken gespeichert und können als Bericht im HTML- oder JSON-Format exportiert werden. Zudem kann man das Tool dasselbe Szenario mehrmals wiederholen lassen und so die Mittelwerte sowie weitere statistische Maße (Median, 90%-Perzentil, 95%-Perzentil, Minimum, Maximum) pro Wiederholung und für alle Wiederholungen zusammen berechnen.
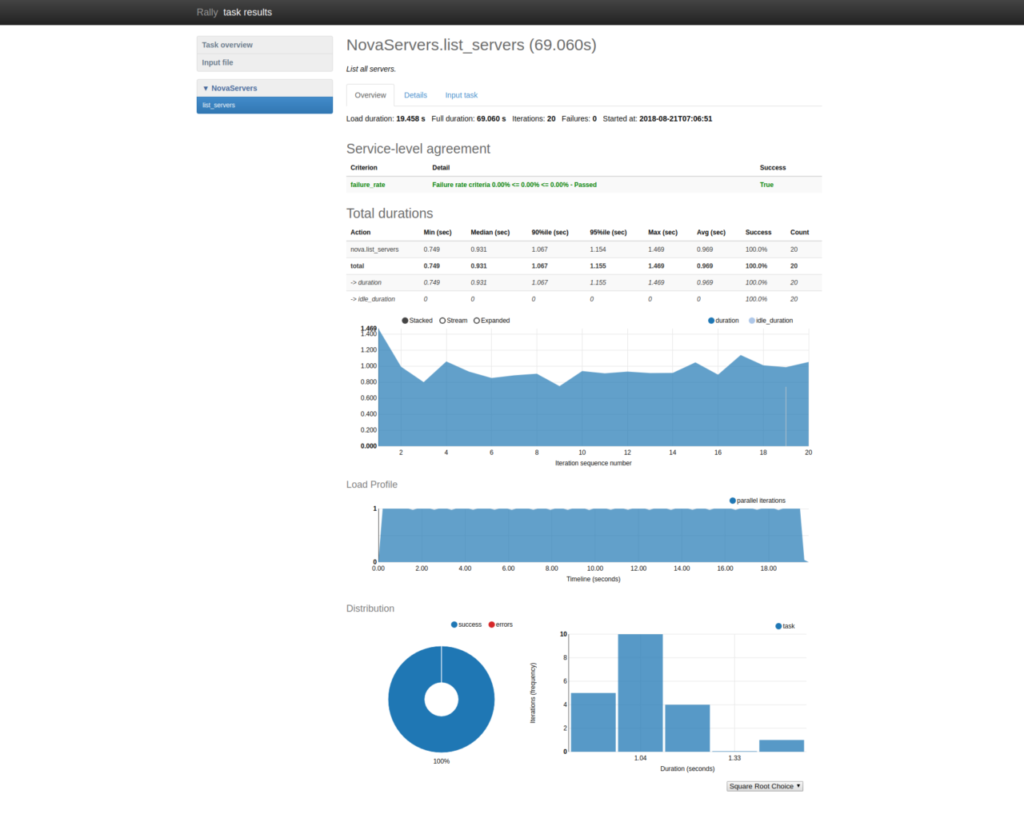
Rally-Testbericht im HTML-Format
Rally unterstützt außerdem das Konzept des Service Level Agreements (SLA). Das heißt, es besteht die Möglichkeit, eine akzeptable Fehlerquote für eine bestimmte Anzahl an Wiederholungen festzulegen, um so beurteilen zu können, ob der gesamte Test erfolgreich war.
Ein weiterer Punkt, der uns bei diesem Projekt sehr angesprochen hat, ist die Möglichkeit, die Tests als Endkunde auszuführen und nicht in der Rolle des Administrators. Wir können uns also komplett in die Lage unserer Public Cloud Kunden versetzen.
Anwendungsfälle
Performance-Messung
Zunächst ist es uns wichtig, die API einer bestehenden Umgebung zu prüfen. Wir führen deshalb mehrmals pro Stunde eine bestimmte Anzahl an Wiederholungen von Rally-Tests für jede OpenStack-Komponente in allen Regionen durch.
Software-Qualifikation
Des Weiteren wollen wir Rally nutzen, wenn wir Code patchen oder Sicherheits- und Softwareupdates vornehmen. In diesen Fällen ist es ohne ein spezifisches Tool schwierig, die Auswirkungen der Änderungen zu messen. Nehmen wir als Beispiel die Kernel-Updates im Zusammenhang mit den letzten Sicherheitslücken (Spectre und Meltdown), denen nachgesagt wurde, dass sie die Performance mindern. Mit Rally können wir mögliche Auswirkungen nun ganz leicht einschätzen.
Hardware-Qualifikation
Rally könnte auch zum Einsatz kommen, wenn wir eine neue Reihe physischer Server testen wollen, die über die „Control Plane“ von OpenStack genutzt werden. Mit dem Tool können wir überprüfen, ob es Schwankungen bei der Performance gibt.
Messungen sind gut und schön, aber ...
Vergessen wir nicht, dass wir die Entwicklung der Antwortzeiten im Zeitverlauf visualisieren wollen. Rally kann uns einen HTML-Bericht zur Ausführung eines Szenarios ausgeben. Dieser bezieht sich also auf eine sehr kurze Zeitspanne. Das Tool kann uns jedoch keinen Bericht ausgeben, in dem alle Ausführungen zusammengefasst sind.
Wir mussten deshalb einen Weg finden, wie wir alle Daten aus den Ausführungsberichten extrahieren und in grafischer Form zusammenfassen. Hier kommt unsere interne Metrics Data Platform ins Spiel, die für die Datenspeicherung auf Warp10 und für Dashboards auf Grafana basiert.
Wir haben die Messwerte der Tests als JSON-Dateien exportiert, was bereits in Rally implementiert ist, und diese auf unsere Metrics Data Platform geladen. Dann haben wir ein Dashboard erstellt, auf dem die Antwortzeiten im zeitlichen Verlauf für jeden Test und für jede Region visualisiert werden. So können wir ganz einfach ihre Entwicklung im zeitlichen Verlauf visualisieren und die Antwortzeiten pro Region miteinander vergleichen. Bei naheliegenden Regionen (in Frankreich beispielsweise: GRA, RBX und SBG) sollten wir ungefähr dieselben Antwortzeiten erhalten. Ist das nicht der Fall, suchen wir nach der Ursache, um das Problem zu beheben.
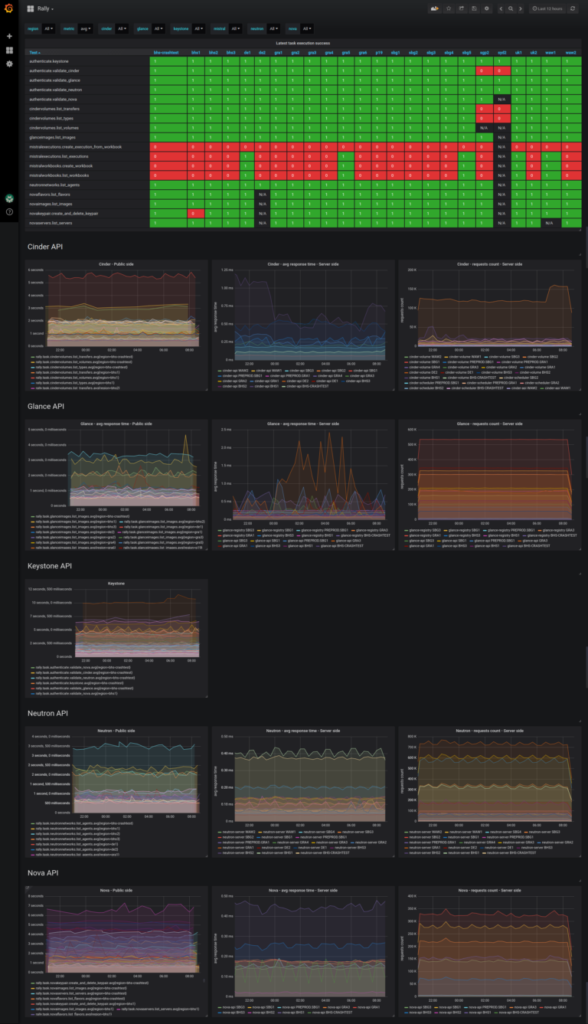
Internes Dashboard mit allen Rally-Testergebnissen
Konkrete Fallstudie
Nachdem wir alle Komponenten eingerichtet hatten, verglichen wir die Entwicklung der Antwortzeiten zwischen den verschiedenen Regionen. Dabei ist uns aufgefallen, dass die Performance sich im zeitlichen Verlauf und für manche Regionen bei bestimmten Tests unseres Projekts verschlechtert hatte. Nehmen wir als Beispiel einen Test, bei dem alle Instanzen des Rally-Projekts aufgelistet werden. Durchschnittlich wurden 600 ms gemessen, aber für einige Regionen waren es 3 Sekunden.
Wir haben zunächst überprüft, ob der Fehler nur bei unserem Projekt auftrat oder bei allen Kunden. Zum Glück trat er nur bei uns auf.
Nach einer tiefergehenden Recherche fanden wir heraus, dass der Engpass auf Datenbankebene des Juno-Releases von OpenStack lag. OpenStack wendet nämlich soft delete beim Löschen von Daten an. Das bedeutet, dass die Daten als gelöscht markiert, aber nicht wirklich aus der Tabelle gelöscht werden. In unserem Fall enthält die Tabelle „instances“ unter anderem die Spalten „project_id“ und „deleted“.Wenn Rally die Server des Projekts listet, lautet die Anfrage:
SELECT * FROM instances WHERE project_id=’xxx’ AND deleted = 0;
Für die Versionen von OpenStack Juno gibt es im Gegensatz zu OpenStack Newton leider keinen Index („project_id“, „deleted“) in dieser Tabelle. Für das Rally-Projekt jeder Region starteten die Tests täglich ungefähr 3000 neue Instanzen. Nach drei Monaten waren 270 000 Instanzen im soft-delete-Status in unseren Datenbanken. Diese riesige Menge an gespeicherten Daten aufgrund eines fehlenden Index in der Tabelle erklärt die Latenzzeiten, die wir für einige Regionen gemessen haben (nur Regionen mit der Juno-Version).
Die Korrekturmaßnahme, die wir für unsere internen Projekte deshalb vorgenommen haben, bestand aus einem Mechanismus, der alle Daten im soft-delete-Status endgültig löscht. Das Ergebnis konnte man sofort sehen. Die Antwortzeiten im Test, bei dem die Server des Rally-Projekts gelistet wurden, konnten durch vier geteilt werden.
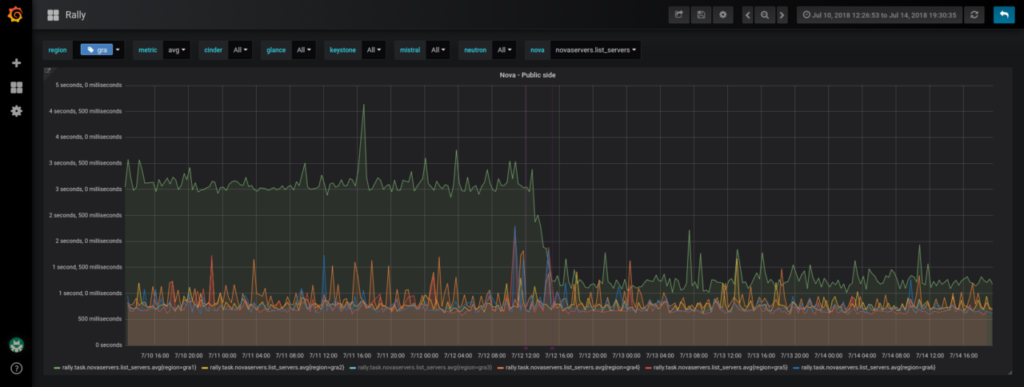
Eindeutige Verbesserung der Antwortzeit einer Region mit Juno im Rally-Projekt
Für diesen speziellen Fall werden wir für unsere Kunden, die eventuell mit denselben Problemen konfrontiert sind, eine automatische Archivierung der Daten im soft-delete-Status in den für solche Zwecke zur Verfügung stehenden shadow tables von OpenStack einrichten.
Dank dieses Benchmark-Tools können wir nun Ungleichheiten zwischen den Regionen aufdecken, die unterschiedliche Nutzererfahrungen verursachen. Wir erarbeiten die notwendigen Lösungen, um diese Unregelmäßigkeiten zu beseitigen und um allen Nutzern in naheliegenden Regionen die bestmögliche Qualität zu liefern. Mit diesem Tool machen wir mehr als Benchmarking. Wir beginnen einen Prozess zur kontinuierlichen Verbesserung unserer Dienste, um die Nutzerqualität unserer OpenStack-APIs zu halten und zu steigern.